

“Bilgi Güvenliği Olayları Görselleştirmesi” yazı disizinin bu bölümünde Apache web loglarının Scalp ile sınıflandırılması ve Logstalgia ile görselleştirilmesini etraflıca ele alıyoruz. Görselleştirmeye geçmeden önce Apache web sunucularına değinip, ardından da logların sınıflandırmasından bahsedeceğiz.
UYARI: Bu yazı ve yazı dizisinin tamamı bir teknik proje halinde bir yüksek lisans programında zaten sunulmuştur. Ayrıca yine bu proje başka bir tezin içeriğini de oluşturmuştur. Bu yüzden bu yazıların ve içindeki herhangi bir bilginin izinsiz alınması, kopyalanması, çoğaltılması ve/veya başka herhangi bir ortamda farklı bir kişi tarafından yazılmış gibi yayınlanması ve kullanılması kesinlikle yasaktır.
Apache web loglarının sınıflandırılması ile görselleştirilmesine geçmeden önce Apache web sunucularından kısaca bahsetmekte fayda var.
APACHE WEB SERVER
Apache, açık kaynak kodlu bir web sunucu programıdır. Birçok işletim sistemi üzerinde çalışmaktadır. Apache’nin World Wide Web’in bu günlere gelmesinde önemli rolleri olmuştur. Dünyada en yaygın kullanılan web sunucusu konumundadır. Apache’nin dünya genelinde %50 civarında bir kullanımı söz konusudur. Apache yazılım vakfı tarafından geliştirilmektedir.
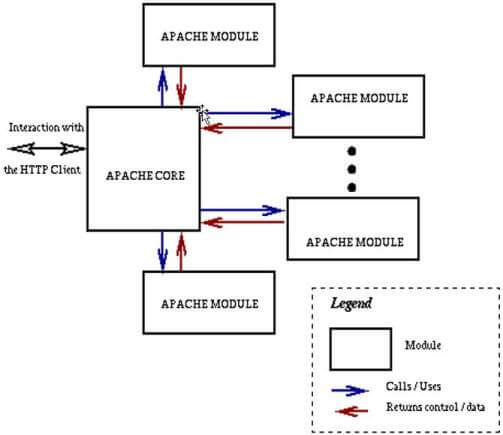
Resim-1: Apache Mimari Yapısı
Apache web server işletim sistemlerine uyumluğunun yanında en temel özelliği modüler yapısıdır. Uygulamanın çekirdek yapısı kurulduktan sonra istenen özellikler modül olarak eklenebilmektedir. Bu da yapının ne kadar esnek olduğunu göstermektedir. Kullanılan bütün web sunucularına olduğu gibi Apache sunucusuna da OWASP TOP 10 [1] listesinde bulunan web uygulama atakları yapılmaktadır. Bu atakların tespit edilebilmesi için ham log dosyasınının ayıklanması ve bu ayıklanan bilginin görselleştirilerek anlamlandırılması gerekmektedir. Bunu yapmanın belli yöntemleri vardır. En temel üç örnek şöyledir:
- Bunlarda bir tanesi gelen web isteklerinin kayıtlarının ekrana yansıtılması (görselleştirilmesi) ve yansıtılan bu görüntüden yapılan atakların tespit edilmesidir.
- Diğer bir yöntem ise Apache kayıt dosyasını ayrıştırarak ve bu ayrıştırılan bilgiler atak vektörleri referans dosyasına göre sınıflandırılmasıdır.
- Son olarak ModSecurity [2] gibi web appication firewall [3] sistemlerinin modül olarak Apache sunucusuna dahil edilmesi ve bu uygulamaların kayıt dosyalarının görselleştirilmesidir.
APACHE WEB LOGLARININ SCALP İLE SINIFLANDIRILMASI
Web sunucu kayıtlarının anlamlandırılması ise genel olarak ayrı bir problemin konusudur. Örneğin bu çalışmada kullanılan Scalp yazılımı Apache loglarının ham halinden ayrıştırıp anlamlandırılması sağlanmıştır. Bu konuda yapılması gereken işlem üç temel adımdan oluşmaktadır.
- İlk olarak bilginin anlandırılmak istenilen kısmını başka bir dosyaya (log, text, html v.b) aktarmak için ayrıştırıcı (parser) kullanılır.
- İkinci bölüm de ise web atak vektörleri için referans dosyası oluşturulmaktadır ve kullanılan ayrıştırıcı (parser), bilgileri anlamlandırmak için kullanacağı XML dosyasıdır.
- Son aşama ise oluşturulan dosyanın görselleştirilmesidir. Görselleştirme istenilen bir yazılım ile yapılabilir [4, 5].
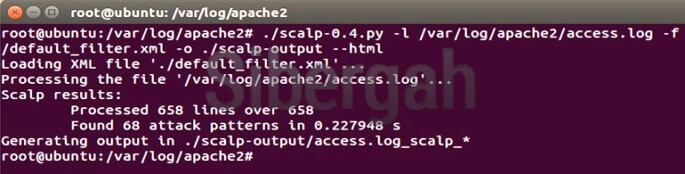
Resim-2: Scalp’ın çalışması
Bir ayrıştırıcı (parser) kullanımıyla Apache web sunucusunun access.log dosyasında bulunan web atak wektörleri dışarı çıkarılmaktadır. Kullandığımız parser alttaki gibidir:
#!/usr/bin/env python
from __future__ import with_statement
import time, base64
import os,sys,re,random
from StringIO import StringIO
try:
from lxml import etree
except ImportError:
try:
import xml.etree.cElementTree as etree
except ImportError:
try:
import xml.etree.ElementTree as etree
except ImportError:
print "Cannot find the ElementTree in your python packages"
__application__ = "scalp"
__version__ = "0.4"
__release__ = __application__ + '/' + __version__
__author__ = "Romain Gaucher"
names = {
'xss' : 'Cross-Site Scripting',
'sqli' : 'SQL Injection',
'csrf' : 'Cross-Site Request Forgery',
'dos' : 'Denial Of Service',
'dt' : 'Directory Traversal',
'spam' : 'Spam',
'id' : 'Information Disclosure',
'rfe' : 'Remote File Execution',
'lfi' : 'Local File Inclusion'
}
c_reg = re.compile(r'^(.+)-(.*)\[(.+)[-|+](\d+)\] "([A-Z]+)?(.+) HTTP/\d.\d" (\d+)(\s[\d]+)?(\s"(.+)" )?(.*)$')
table = {}
txt_header = """
#
# File created by Scalp! by Romain Gaucher - http://code.google.com/p/apache-scalp
# Apache log attack analysis tool based on PHP-IDS filters
#
"""
xml_header = """<!--
File created by Scalp! by Romain Gaucher - http://code.google.com/p/apache-scalp
Apache log attack analysis tool based on PHP-IDS filters
-->
<?xml version="1.0" encoding="utf-8"?>
"""
html_header = """<html><head><style>
html, body {background-color:#ccc;color:#222;font-family:'Lucida Grande',Verdana,Arial,Sans-Serif;font-size:0.8em;line-height:1.6em;margin:0;padding:0;}
body {background-color:#fff;padding:0; margin: 15px; border: 1px solid #444;}
h1 { display: block; border-bottom: 2px solid #333; padding: 5px;}
h2 { display: block; font-size: 1.5em; font-weight: 700; background-color: #efefef;margin:10px;padding-left: 15px;}
.match { display: block; margin: 10px; border: 1px solid; padding: 5px;}
.impact { float: right; background-color: #fff; border: 1px solid #ccc; padding: 5px; font-size: 1.8em;}
.impact-1,.impact-2,.impact-3 { background-color: #f2ffe0; border-color: #DEF0C3;}
.impact-4,.impact-5 { background-color: #ffe6bf; border-color: #ffd38f;}
.impact-6,.impact-7,.impact-8,.impact-9,.impact-10,.impact-11 /*...*/ { background-color: #FFEDEF; border-color: #FFC2CA;}
.block {display:block; margin:5px;}
.highlight {margin: 5px;}
.reason {font-weight: 700; color: #444;}
.line, .regexp {border-bottom: 1px solid #ccc; border-right: 1px solid #ccc; background-color: #fff; padding: 2px; margin: 10px;}
#footer {text-align: center;}
</style></head><body>"""
html_footer = "<div id='footer'>Scalp by Romain Gaucher <[email protected]> - <a href='http://rgaucher.info'>http://rgaucher.info</a></div></body></html>"
class object_dict(dict):
def __init__(self, initd=None):
if initd is None:
initd = {}
dict.__init__(self, initd)
def __getattr__(self, item):
d = self.__getitem__(item)
# if value is the only key in object, you can omit it
if isinstance(d, dict) and 'value' in d and len(d) == 1:
return d['value']
else:
return d
def __setattr__(self, item, value):
self.__setitem__(item, value)
def __parse_node(node):
tmp = object_dict()
# save attrs and text, hope there will not be a child with same name
if node.text:
tmp['value'] = node.text
for (k,v) in node.attrib.items():
tmp[k] = v
for ch in node.getchildren():
cht = ch.tag
chp = __parse_node(ch)
if cht not in tmp: # the first time, so store it in dict
tmp[cht] = chp
continue
old = tmp[cht]
if not isinstance(old, list):
tmp.pop(cht)
tmp[cht] = [old] # multi times, so change old dict to a list
tmp[cht].append(chp) # add the new one
return tmp
def parse(xml_file):
try:
xml_handler = open(xml_file, 'r')
doc = etree.parse(xml_handler).getroot()
xml_handler.close()
return object_dict({doc.tag: __parse_node(doc)})
except IOError:
print "error: problem with the filter's file"
return {}
def get_value(array, default):
if 'value' in array:
return array['value']
return default
def html_entities(str):
out = ""
for i in str:
if i == '"': out += '"'
elif i == '<': out += '<'
elif i == '>': out += '>'
else:
out += i
return out
d_replace = {
"\r":";",
"\n":";",
"\f":";",
"\t":";",
"\v":";",
"'":"\"",
"+ACI-":"\"",
"+ADw-":"<",
"+AD4-" : ">",
"+AFs-" : "[",
"+AF0-" : "]",
"+AHs-" : "{",
"+AH0-" : "}",
"+AFw-" : "\\",
"+ADs-" : ";",
"+ACM-" : "#",
"+ACY-" : "&",
"+ACU-" : "%",
"+ACQ-" : "$",
"+AD0-" : "=",
"+AGA-" : "'",
"+ALQ-" : "\"",
"+IBg-" : "\"",
"+IBk-" : "\"",
"+AHw-" : "|",
"+ACo-" : "*",
"+AF4-" : "^",
"+ACIAPg-" : "\">",
"+ACIAPgA8-" : "\">",
}
re_replace = None
def fill_replace_dict():
global d_replace, re_replace
# very first control-chars
for i in range(0,20):
d_replace["%%%x" % i] = "%00"
d_replace["%%%X" % i] = "%00"
# javascript charcode
for i in range(33,127):
c = "%c" % i
d_replace["\\%o" % i] = c
d_replace["\\%x" % i] = c
d_replace["\\%X" % i] = c
d_replace["0x%x" % i] = c
d_replace["&#%d;" % i] = c
d_replace["&#%x;" % i] = c
d_replace["&#%X;" % i] = c
# SQL words?
d_replace["is null"]="=0"
d_replace["like null"]="=0"
d_replace["utc_time"]=""
d_replace["null"]=""
d_replace["true"]=""
d_replace["false"]=""
d_replace["localtime"]=""
d_replace["stamp"]=""
d_replace["binary"]=""
d_replace["ascii"]=""
d_replace["soundex"]=""
d_replace["md5"]=""
d_replace["between"]="="
d_replace["is"]="="
d_replace["not in"]="="
d_replace["xor"]="="
d_replace["rlike"]="="
d_replace["regexp"]="="
d_replace["sounds like"]="="
re_replace = re.compile("(%s)" % "|".join(map(re.escape, d_replace.keys())))
def multiple_replace(text):
return re_replace.sub(lambda mo: d_replace[mo.string[mo.start():mo.end()]], text)
# the decode engine tries to detect then decode...
def decode_attempt(string):
return multiple_replace(string)
def analyzer(data):
exp_line, regs, array, preferences, org_line = data[0],data[1],data[2],data[3],data[4]
done = []
# look for the detected attacks...
# either stop at the first found or not
for attack_type in preferences['attack_type']:
if attack_type in regs:
if attack_type not in array:
array[attack_type] = {}
for _hash in regs[attack_type]:
if _hash not in done:
done.append(_hash)
attack = table[_hash]
cur_line = exp_line[5]
if preferences['encodings']:
cur_line = decode_attempt(cur_line)
if attack[0].search(cur_line):
if attack[1] not in array[attack_type]:
array[attack_type][attack[1]] = []
array[attack_type][attack[1]].append((exp_line, attack[3], attack[2], org_line))
if preferences['exhaustive']:
break
else:
return
def scalper(access, filters, preferences = [], output = "text"):
global table
if not os.path.isfile(access):
print "error: the log file doesn't exist"
return
if not os.path.isfile(filters):
print "error: the filters file (XML) doesn't exist"
print "please download it at https://svn.php-ids.org/svn/trunk/lib/IDS/default_filter.xml"
return
if output not in ('html', 'text', 'xml'):
print "error: the output format '%s' hasn't been recognized" % output
return
# load the XML file
xml_filters = parse(filters)
len_filters = len(xml_filters)
if len_filters < 1:
return
# prepare to load the compiled regular expression
regs = {} # type => (reg.compiled, impact, description, rule)
print "Loading XML file '%s'..." % filters
for group in xml_filters:
for f in xml_filters[group]:
if f == 'filter':
if type(xml_filters[group][f]) == type([]):
for elmt in xml_filters[group][f]:
rule, impact, description, tags = "",-1,"",[]
if 'impact' in elmt:
impact = get_value(elmt['impact'], -1)
if 'rule' in elmt:
rule = get_value(elmt['rule'], "")
if 'description' in elmt:
description = get_value(elmt['description'], "")
if 'tags' in elmt and 'tag' in elmt['tags']:
if type(elmt['tags']['tag']) == type([]):
for tag in elmt['tags']['tag']:
tags.append(get_value(tag, ""))
else:
tags.append(get_value(elmt['tags']['tag'], ""))
# register the entry in our array
for t in tags:
compiled = None
if t not in regs:
regs[t] = []
try:
compiled = re.compile(rule)
except Exception:
print "The rule '%s' cannot be compiled properly" % rule
return
_hash = hash(rule)
if impact > -1:
table[_hash] = (compiled, impact, description, rule, _hash)
regs[t].append(_hash)
if len(preferences['attack_type']) < 1:
preferences['attack_type'] = regs.keys()
flag = {} # {type => { impact => ({log_line dict}, rule, description, org_line) }}
print "Processing the file '%s'..." % access
sample, sampled_lines = False, []
if preferences['sample'] != float(100):
# get the number of lines
sample = True
total_nb_lines = sum(1 for line in open(access))
# take a random sample
random.seed(time.clock())
sampled_lines = random.sample(range(total_nb_lines), int(float(total_nb_lines) * preferences['sample'] / float(100)))
sampled_lines.sort()
loc, lines, nb_lines = 0, 0, 0
old_diff = 0
start = time.time()
diff = []
with open(access) as log_file:
for line in log_file:
lines += 1
if sample and lines not in sampled_lines:
continue
if c_reg.match(line):
out = c_reg.search(line)
ip = out.group(1)
name = out.group(2)
date = out.group(3)
ext = out.group(4)
method = out.group(5)
url = out.group(6)
response = out.group(7)
byte = out.group(8)
referrer = out.group(9)
agent = out.group(10)
if not correct_period(date, preferences['period']):
continue
loc += 1
if len(url) > 1 and method in ('GET','POST','HEAD','PUT','PUSH','OPTIONS'):
analyzer([(ip,name,date,ext,method,url,response,byte,referrer,agent),regs,flag, preferences, line])
elif preferences['except']:
diff.append(line)
# mainly testing purposes...
if nb_lines > 0 and lines > nb_lines:
break
tt = time.time() - start
n = 0
for t in flag:
for i in flag[t]:
n += len(flag[t][i])
print "Scalp results:"
print "\tProcessed %d lines over %d" % (loc,lines)
print "\tFound %d attack patterns in %f s" % (n,tt)
short_name = access[access.rfind(os.sep)+1:]
if n > 0:
print "Generating output in %s%s%s_scalp_*" % (preferences['odir'],os.sep,short_name)
if 'html' in preferences['output']:
generate_html_file(flag, short_name, filters, preferences['odir'])
elif 'text' in preferences['output']:
generate_text_file(flag, short_name, filters, preferences['odir'])
elif 'xml' in preferences['output']:
generate_xml_file(flag, short_name, filters, preferences['odir'])
# generate exceptions
if len(diff) > 0:
o_except = open(os.path.abspath(preferences['odir'] + os.sep + "scalp_except.txt"), "w")
for l in diff:
o_except.write(l + '\n')
o_except.close()
def generate_text_file(flag, access, filters, odir):
curtime = time.strftime("%a-%d-%b-%Y", time.localtime())
fname = '%s_scalp_%s.txt' % (access, curtime)
fname = os.path.abspath(odir + os.sep + fname)
try:
out = open(fname, 'w')
out.write(txt_header)
out.write("Scalped file: %s\n" % access)
out.write("Creation date: %s\n\n" % curtime)
for attack_type in flag:
if attack_type in names:
out.write("Attack %s (%s)\n" % (names[attack_type], attack_type))
else:
out.write("Attack type: %s\n" % attack_type)
impacts = flag[attack_type].keys()
impacts.sort(reverse=True)
for i in impacts:
out.write("\n\t### Impact %d\n" % int(i))
for e in flag[attack_type][i]:
out.write("\t%s" % e[3])
out.write("\tReason: \"%s\"\n\n" % e[2])
out.close()
except IOError:
print "Cannot open the file:", fname
return
def generate_xml_file(flag, access, filters, odir):
curtime = time.strftime("%a-%d-%b-%Y", time.localtime())
fname = '%s_scalp_%s.xml' % (access, curtime)
fname = os.path.abspath(odir + os.sep + fname)
try:
out = open(fname, 'w')
out.write(xml_header)
out.write("<scalp file=\"%s\" time=\"%s\">\n" % (access, curtime))
for attack_type in flag:
name = ""
if attack_type in names:
name = " name=\"%s\"" % names[attack_type]
out.write(" <attack type=\"%s\"%s>\n" % (attack_type, name))
impacts = flag[attack_type].keys()
impacts.sort(reverse=True)
for i in impacts:
out.write(" <impact value=\"%d\">\n" % int(i))
for e in flag[attack_type][i]:
out.write(" <item>\n")
out.write(" <reason><![CDATA[%s]]></reason>\n" % e[2])
out.write(" <line><![CDATA[%s]]></line>\n" % e[3])
out.write(" </item>\n")
out.write(" </impact>\n")
out.write(" </attack>\n")
out.write("</scalp>")
out.close()
except IOError:
print "Cannot open the file:", fname
return
return
def generate_html_file(flag, access, filters, odir):
curtime = time.strftime("%a-%d-%b-%Y", time.localtime())
fname = '%s_scalp_%s.html' % (access, curtime)
fname = os.path.abspath(odir + os.sep + fname)
try:
out = open(fname, 'w')
out.write(html_header)
out.write("<h1>Scalp of %s [%s]</h1>\n" % (access, curtime))
for attack_type in flag:
name = ""
if attack_type in names:
name = "%s" % names[attack_type]
if len(flag[attack_type].values()) < 1:
continue
out.write(" <h2>%s (%s)</h2>\n" % (attack_type, name))
impacts = flag[attack_type].keys()
impacts.sort(reverse=True)
# order by impact
for i in impacts:
out.write("<div class='match impact-%d'>\n" % int(i))
out.write(" <div class='impact'>Impact %d</div>\n" % int(i))
# list the one of same impacts
for e in flag[attack_type][i]:
out.write(" <div class='block highlight'>\n")
out.write(" Reason: <span class='reason'>%s</span><br />\n" % html_entities(e[2]))
out.write(" <span class='line'><b>Log line:</b>%s</span><br />\n" % html_entities(e[0][5]))
out.write(" <span class='regexp'><b>Matching Regexp:</b>%s</span>\n" % html_entities(e[1]))
out.write(" </div>\n")
out.write("</div>\n")
out.write("<br />\n")
out.write(html_footer)
out.close()
except IOError:
print "Cannot open the file:", fname
return
months = ['Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
def correct_period(date, period):
date = date.replace(':', '/')
l_date = date.split('/')
for i in (2,1,0,3,4,5):
if i != 1:
cur = int(l_date[i])
if cur < period['start'][i] or cur > period['end'][i]:
return False
else:
cur = months.index(l_date[i])
if cur == -1:
return False
if cur < period['start'][i] or cur > period['end'][i]:
return False
return True
def analyze_date(date):
"""04/Apr/2008:15:45;*/May/2008"""
d_min = [01, 00, 0000, 00, 00, 00]
d_max = [31, 11, 9999, 24, 59, 59]
date = date.replace(':', '/')
l_date = date.split(';')
l_start= l_date[0].split('/')
l_end = l_date[1].split('/')
v_start = [01, 00, 0000, 00, 00, 00]
v_end = [31, 11, 9999, 24, 59, 59]
for i in range(len(l_start)):
if l_start[i] == '*': continue
else:
if i == 1:
v_start[1] = months.index(l_start[1])
else:
cur = int(l_start[i])
if cur < d_min[i]: v_start[i] = d_min[i]
elif cur > d_max[i]: v_start[i] = d_max[i]
else: v_start[i] = cur
for i in range(len(l_end)):
if l_end[i] == '*': continue
else:
if i == 1:
v_end[1] = months.index(l_end[1])
else:
cur = int(l_end[i])
if cur < d_min[i]: v_end[i] = d_min[i]
elif cur > d_max[i]: v_end[i] = d_max[i]
else: v_end[i] = cur
return {'start' : v_start, 'end' : v_end}
def help():
print "Scalp the apache log! by Romain Gaucher - http://rgaucher.info"
print "usage: ./scalp.py [--log|-l log_file] [--filters|-f filter_file] [--period time-frame] [OPTIONS] [--attack a1,a2,..,an]"
print " [--sample|-s 4.2]"
print " --log |-l: the apache log file './access_log' by default"
print " --filters |-f: the filter file './default_filter.xml' by default"
print " --exhaustive|-e: will report all type of attacks detected and not stop"
print " at the first found"
print " --tough |-u: try to decode the potential attack vectors (may increase"
print " the examination time)"
print " --period |-p: the period must be specified in the same format as in"
print " the Apache logs using * as wild-card"
print " ex: 04/Apr/2008:15:45;*/Mai/2008"
print " if not specified at the end, the max or min are taken"
print " --html |-h: generate an HTML output"
print " --xml |-x: generate an XML output"
print " --text |-t: generate a simple text output (default)"
print " --except |-c: generate a file that contains the non examined logs due to the"
print " main regular expression; ill-formed Apache log etc."
print " --attack |-a: specify the list of attacks to look for"
print " list: xss, sqli, csrf, dos, dt, spam, id, ref, lfi"
print " the list of attacks should not contains spaces and comma separated"
print " ex: xss,sqli,lfi,ref"
print " --output |-o: specifying the output directory; by default, scalp will try to write"
print " in the same directory as the log file"
print " --sample |-s: use a random sample of the lines, the number (float in [0,100]) is"
print " the percentage, ex: --sample 0.1 for 1/1000"
def main(argc, argv):
filters = "default_filter.xml"
access = "access_log"
output = ""
preferences = {
'attack_type' : [],
'period' : {
'start' : [01, 00, 0000, 00, 00, 00],# day, month, year, hour, minute, second
'end' : [31, 11, 9999, 24, 59, 59]
},
'except' : False,
'exhaustive' : False,
'encodings' : False,
'output' : "",
'odir' : os.path.abspath(os.curdir),
'sample' : float(100)
}
if argc < 2 or sys.argv[1] == "--help":
help()
sys.exit(0)
else:
for i in range(argc):
s = argv[i]
if i < argc:
if s in ("--filters","-f"):
filters = argv[i+1]
elif s in ("--log","-l"):
access = argv[i+1]
elif s in ("--output", "-o"):
preferences['odir'] = argv[i+1]
elif s in ("--sample", "-s"):
try:
preferences['sample'] = float(argv[i+1])
except:
preferences['sample'] = float(4.2)
print "/!\ Error in the sample size, will be 4.2%"
elif s in ("--period", "-p"):
preferences['period'] = analyze_date(argv[i+1])
elif s in ("--exhaustive", "-e"):
preferences['exhaustive'] = True
elif s in ("--html", "-h"):
preferences['output'] += ",html"
elif s in ("--xml", "-x"):
preferences['output'] += ",xml"
elif s in ("--text", "-t"):
preferences['output'] += ",text"
elif s in ("--except", "-c"):
preferences['except'] = True
elif s in ("--tough","-u"):
fill_replace_dict()
preferences['encodings'] = True
elif s in ("--attack", "-a"):
preferences['attack_type'] = argv[i+1].split(',')
else:
print "argument error, '%s' has been ignored" % s
if len(preferences['output']) < 1:
preferences['output'] = "text"
if not os.path.isdir(preferences['odir']):
print "The directory %s doesn't exist, scalp will try to create it"
try:
os.mkdir(preferences['odir'])
except:
print "/!\ scalp cannot write in",preferences['odir']
print "/!\ Ising /tmp/scalp/ as new directory..."
preferences['odir'] = '/tmp/scalp'
os.mkdir(preferences['odir'])
scalper(access, filters, preferences)
if __name__ == "__main__":
main(len(sys.argv), sys.argv)
"""
import hotshot
from hotshot import stats
name = "hotshot_scalp_stats"
if not os.path.isfile(name):
prof = hotshot.Profile(name)
prof.runcall(main)
prof.close()
s = stats.load(name)
s.sort_stats("time").print_stats()
"""
Sonuç alttaki gibidir:
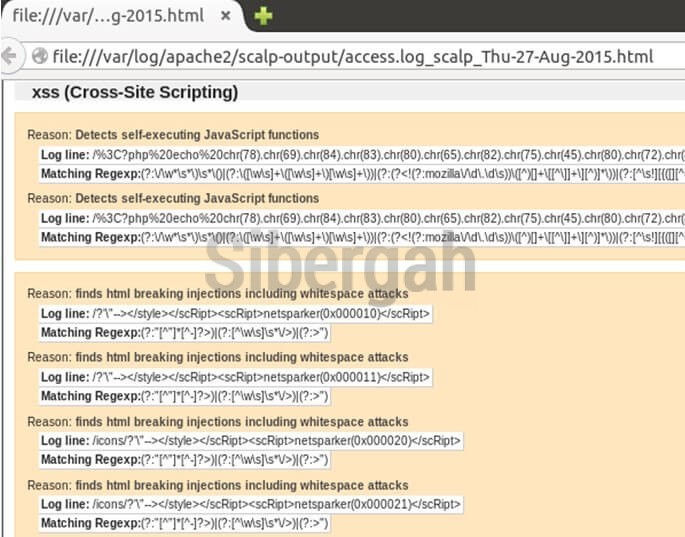
Resim-3: Saldırı logu sınıflandırması
APACHE WEB LOGLARININ LOGSTALGIA İLE GÖRSELLEŞTİRİLMESİ
Logstalgia (Apachepong) pinpon topları görselini kullanarak web sunucularının günlük web trafiklerini görselleştiren bir açık kaynak kodlu projedir. Yapılan web isteklerini görselde bulunan pinpon topları ile eşleştirmiş ve bu topların hedefe çarpması sonucu çıkan sonucu HTTP kodları (200, 303, 404 v.b.) ile göstermektedir. Genel yapı olarak kurulumu pratik olmakla beraber Ubuntu dağıtımına kurulumu yapılarak Apache logları görselleştirilmiştir. Apache, nginx, IIS gibi çeşitli web sunucularını desteklemektedir. Bu uygulama ile özellikle DDoS, SQL injection v.b. gibi ataklar rahatlıkla görselleştirilebilmektedir. Kısaca kurulum aşamaları aşağıdaki gibidir:
$ sudo apt-get install logstalgia $ sudo apt-get install libsdl1.2-dev libsdl-image1.2-dev libpcre3-dev libftgl-dev libpng12-dev libjpeg62-dev $ cd /tmp $ wget https://logstalgia.googlecode.com/files/logstalgia-1.0.3.tar.gz $ tar xvf logstalgia-1.0.3.tar.gz $ cd logstalgia $ ./configure $ make $ sudo make install $ logstalgia -1280x720 --output-ppm-stream output.ppm /var/log/apache2/access.log
Kullanılan senoryada Ubuntu işletim sistemi uzerine Apache kurulumu yapılmıştır ve web servisleri aktif edilmiştir. Diğer sanal Windows üzerinde Netsparker web uygulamaları güvenlik tarama aracı kullanılarak web atak yapılmıştır [6]. Sonuçlarının ekran görüntüsünü alımıştır.

Resim-4: Netsparker saldırı uygulaması
Netsparker ürününü Apache web servisine açıklık analizi yapmak için kullanıldık. Netsparker kullanılarak oluşan web sunucusunun kayıtları Logstalgia ile görselleştirilebilmektedir.
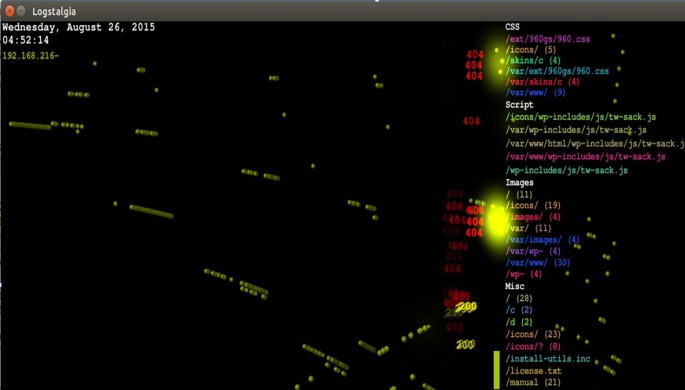
Resim-5: Logstalgia ile görselleştirme
Ayrıca Logstalgia ile ilgili olarak daha önce yapılmış örnek bir kayıdın video görüntüsüne bu adresten ulaşabilirsiniz. Bir sonraki bölümde görüşmek üzere…
Referanslar
- https://www.owasp.org/index.php/Top_10_2013-Top_10
- http://www.modsecurity.org/documentation/contributed/ModSecurity_2.1.0_Turkish.pdf
- http://www.webguvenligi.org/docs/ModSecurity_2.1.0_Turkish.pdf
- https://dev.itratos.de/projects/php-ids/repository/raw/trunk/lib/IDS/default_filter.xml
- https://code.google.com/p/apache-scalp/
- https://www.netsparker.com/web-vulnerability-scanner/
- https://www.youtube.com/watch?v=K8muK-o80ZU